Information Gathering
# Information Gathering
信息收集:
- 狭义的信息收集指的是收集厂商的资产,比如域名和 ip 等等
- 广义的信息收集指的是收集厂商相关的各种信息,包括但不限于员工信息,泄露的源码,泄露的账号密码等等
资产:
- 狭义的厂商的资产一般指代所属这个厂商的域名和 ip
- 广义的资产指的是厂商的域名和 ip 以及每个端口上面开的服务的总和,还包括各种 apk , exe 文件
包括属于厂商的 github, gitlab, slack, 谷歌内部组(相当于国外版钉钉),拥有的云上数据等等等等,在赛博空间属于厂商
的有价值总和都叫厂商的资产,但是资产属于厂商不等于资产在赏金收录范围
必要性:
如果一个厂商的赏金范围只有几个有限的主要域名,也应该对子域名进行信息收集,路径和参数
可能会重用,对子域名进行信息收集然后对范围内域名进行爆破可以扩大该域名的测试面,又或
者某个不在范围的子域名泄露的账号密码尝试在范围的域名进行登录等等
# part1:ASN 分析
ASN(Autonomous System Number,自治系统号码)是一个用于标识自治系统(Autonomous System, AS)的唯一编号。自治系统是指在单一的技术管理下,通过一组路由器和路由表使用相同的内部路由策略和策略集对外进行路由选择的网络或一组网络。ASN 主要用于互联网路由,为每个自治系统分配一个唯一的号码,使得不同的自治系统之间能够进行路由信息的交换。
ASN 由互联网号码分配机构(IANA)分配,并通过区域互联网注册管理机构(RIR)进一步分配给本地的互联网服务提供商(ISP)或其他网络运营机构。目前,ASN 有两种格式:16 位的和 32 位的。传统上,ASN 使用 16 位表示,范围是 1 到 65535。由于互联网的快速发展,16 位 ASN 的数量已经不够用,因此引入了 32 位 ASN,范围从 65536 到 4294967295。
ASN 在互联网协议(IP)网络中起着重要作用,特别是在边界网关协议(BGP)中,BGP 是用于在不同的自治系统之间传递路由信息的协议。每个自治系统通过 ASN 来标识自己,并在 BGP 路由表中进行路由选择。
301 计网大师兴神告诉我简洁点讲就是:一 “群” 路由的编号
先从 bgp 网站获取 asn 码
Hurricane Electric BGP Toolkit (he.net)
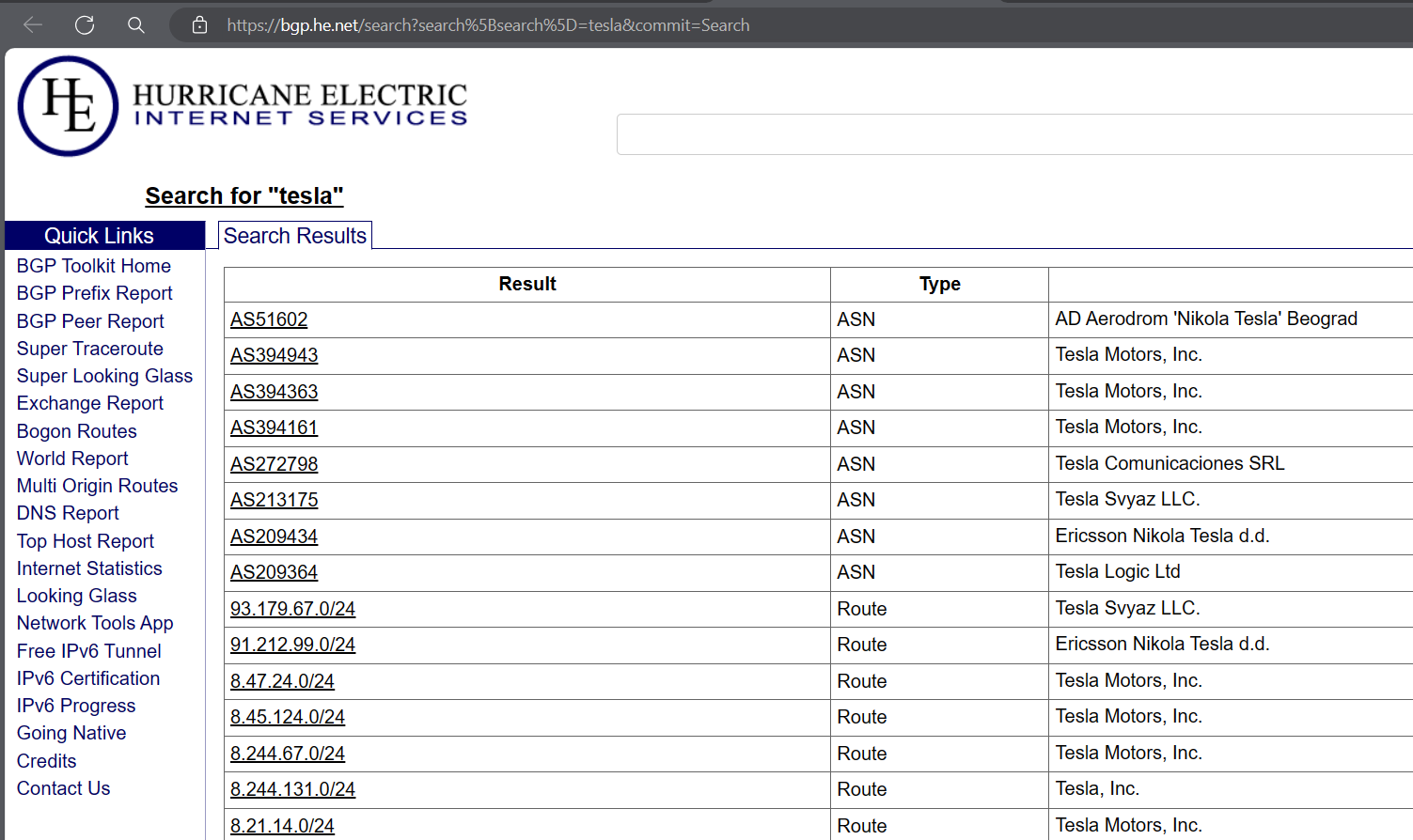
然后用 asnmap 获取 ip 范围
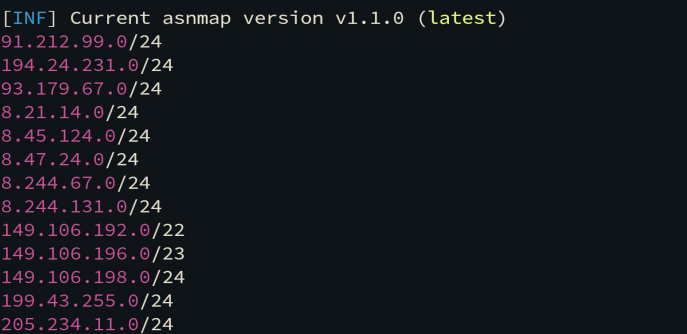
1. 如何从 ipscope.txt 转变成完整的 ips.txt, 也就是从 ip 范围变成 ip 列表?
cat ipscope.txt | mapcidr | tee ips.txt
2. 获取 ip 列表的作用是什么?
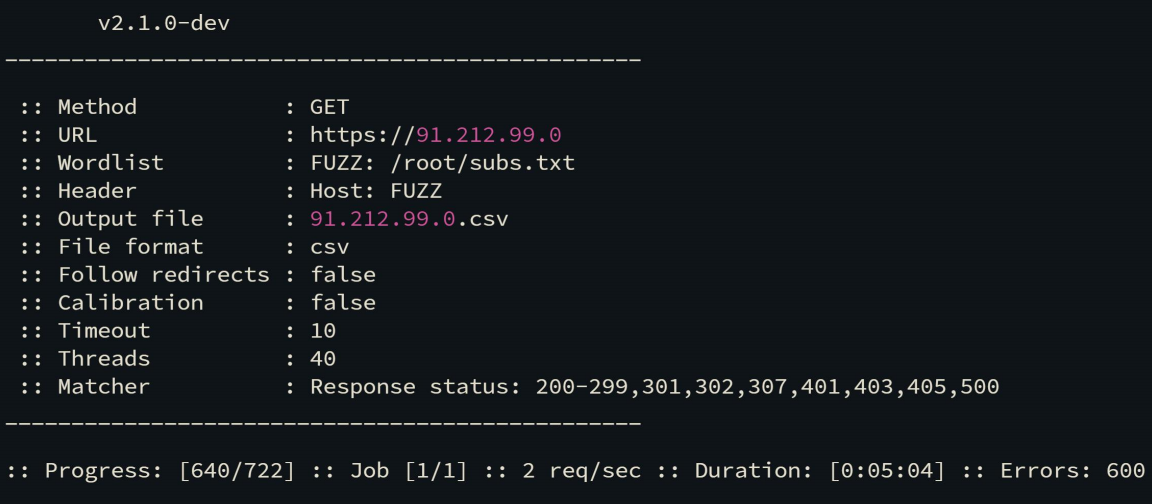
爆破: ips.txt:subs.txt
for i in $(cat ips.txt); do ffuf -w subs.txt -u https://$i -H "HOST: FUZZ" -of csv -o $i.csv; done
# part2:反向 WHOIS
反向 WHOIS 是通过注册信息,像组织名或者所有者邮箱,来获取发现目标厂商的关联域的一种方法
tips:旧的组织名可能会有更多资产
适用于收录漏洞是大范围的厂商
Domain Research Suite (whoisxmlapi.com)

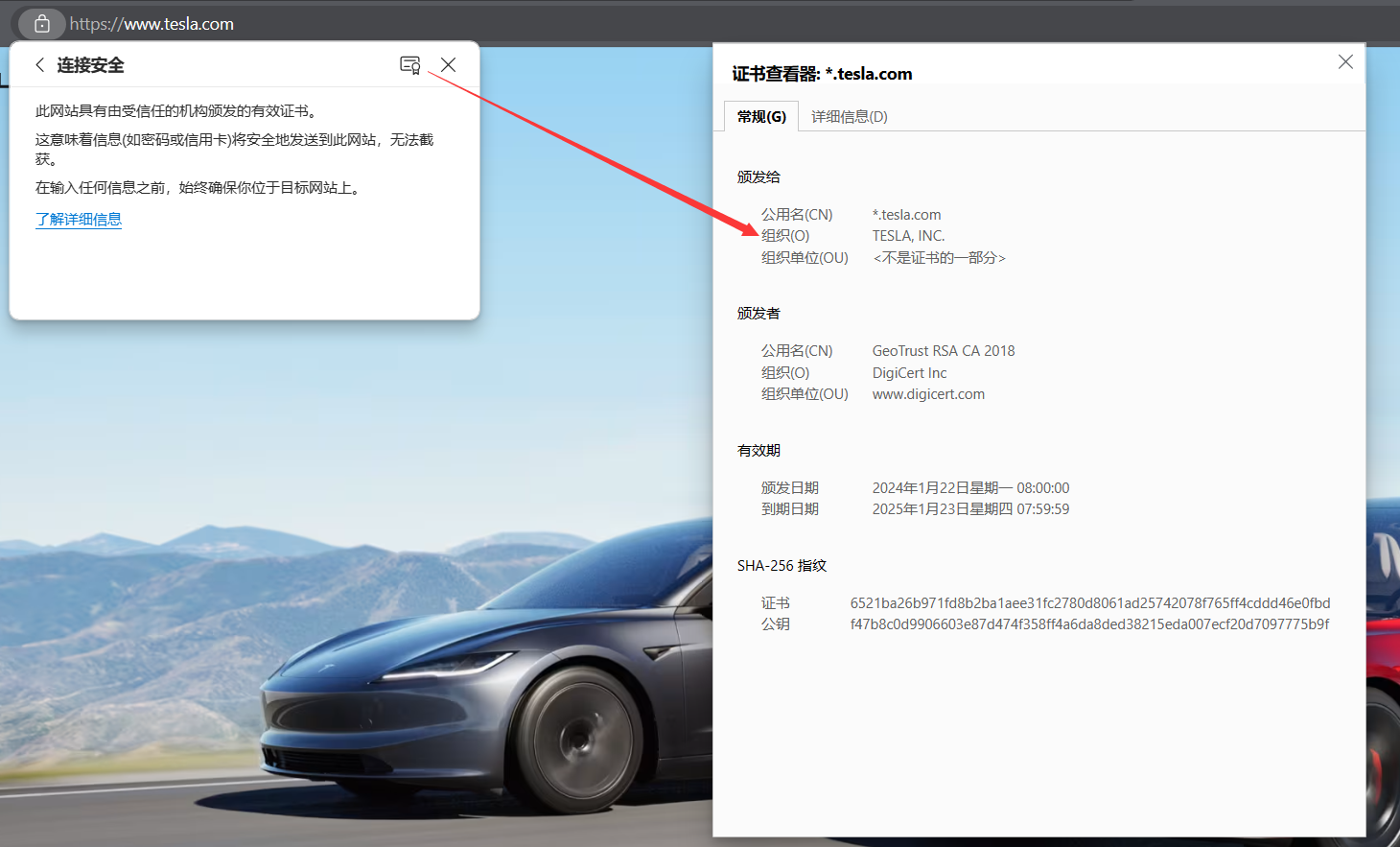
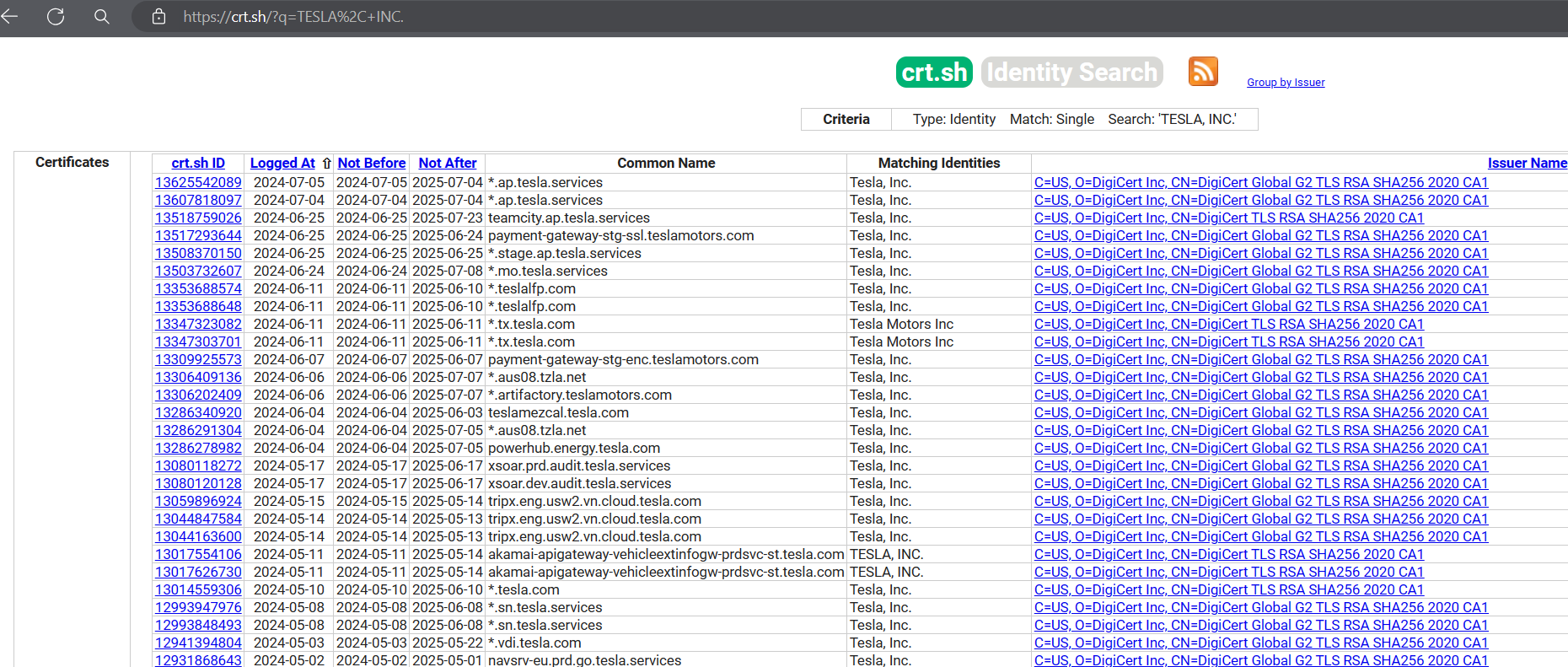
# part3:Certificate 分析
证书:
# Part 4 TLDs 扫描
TLDs (Top-level Domain),就是顶级域,拿 www.starbucks.com 举例,.com 就是 TLD,对于 www.starbucks.com.cn 来说,.com.cn 就是 TLD
当你遇到资产范围写着 *.example.* 的时候,说明厂商业务遍布全球,有时候厂商会明确告诉你区域,但有时候是不告诉你,而不同地区的业务一般都存在差异性
对原本的 www.example.FUZZ 进行爆破,获取这个厂商更广泛的业务以及某些区域的才有的业务,扩大测试面
# Part 5 枚举 Apex 域名
- Apex 域名,就是根域名,例如 www.tesla.com 里面的 Apex 域名,即为 tesla.com
# Part 6 Shodan
Shodan 是一个专门用于搜索和分析互联网连接设备的搜索引擎。与传统的搜索引擎不同,Shodan 不索引网页内容,而是扫描和索引公开暴露在互联网上的设备及其相关信息。它被称为 “黑客的搜索引擎”,因为它能发现各种在线设备,包括但不限于:
- Web 服务器(HTTP、HTTPS)
- 数据库服务器(如 MongoDB、MySQL)
- 工业控制系统(SCADA、ICS)
- 物联网(IoT)设备(智能家居设备、摄像头、路由器)
- VPN 服务器
- 网络存储设备(NAS)
主要功能和用途
- 安全研究:Shodan 是安全研究人员和白帽黑客常用的工具,用于发现未加固或配置不当的设备和服务。
- 网络监控:网络管理员可以使用 Shodan 来监控其网络中公开暴露的设备和服务,确保没有误配置的设备暴露在互联网上。
- 威胁情报:Shodan 提供有关互联网威胁的情报,帮助企业和安全机构了解全球互联网设备的安全状况。
- 攻击面评估:企业可以使用 Shodan 评估其互联网暴露面,确定可能的攻击入口。
快速测试根域名是否值得深度测试
语法:
- ssl.cert.subject.cn:*.tesla.com
- ssl:.tesla.com
- ssl:"Tesla Inc."
- org:"Tesla Inc."
基本语法
-
关键词搜索:可以输入任何关键词来搜索相关的设备。
1
apache
-
精确短语搜索:使用引号来搜索精确短语。
1
"Apache 2.4.1"
过滤器
-
hostname:查找特定主机名的设备。
1
hostname:example.com
-
net:查找特定 IP 范围内的设备。
1
net:192.168.1.0/24
-
port:查找特定端口上的设备。
1
port:22
-
os:查找运行特定操作系统的设备。
1
os:Windows
-
country:查找特定国家的设备。
1
country:US
-
city:查找特定城市的设备。
1
city:"New York"
-
before/after:查找在特定日期之前或之后发现的设备。
1
after:2022-01-01
组合查询
可以组合多个过滤器来精确搜索。例如,查找在特定端口上运行的特定服务,并且位于特定国家的设备:
1 | apache port:80 country:US |
特殊过滤器
-
org:查找特定组织的设备。
1
org:"Google"
-
isp:查找特定 ISP 的设备。
1
isp:"Comcast"
-
product:查找特定产品或服务的设备。
1
product:"Microsoft IIS"
-
version:查找特定版本的软件或服务的设备。
1
version:"7.5"
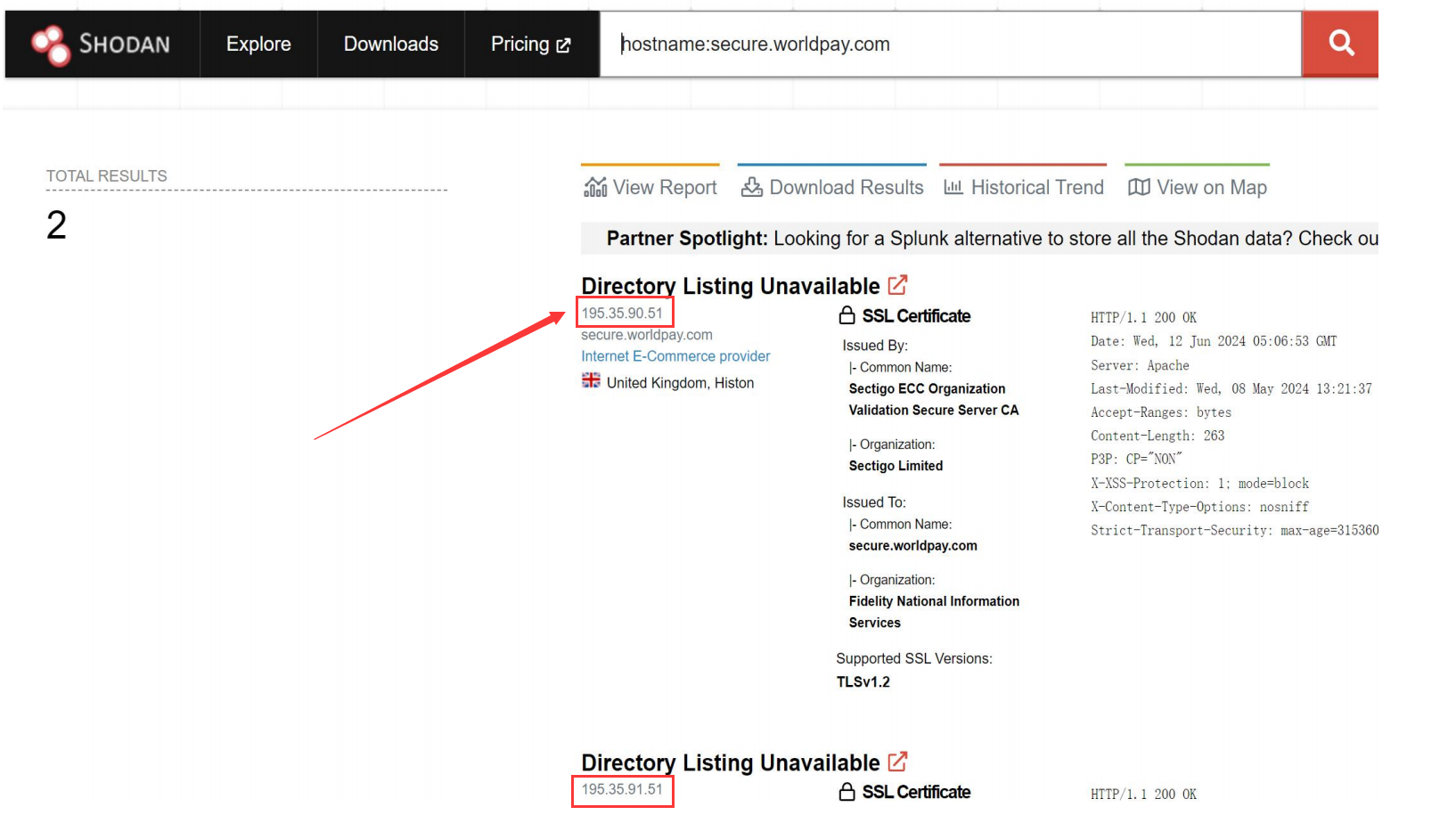
用 shodan 的语法找出该域名的真实 IP 绕过位于 CDN 上的服务器的速率限制:
hostname:secure.worldpay.com
# part7 NEtlas
- 通过组织名提取根域名
netlas download -d whois-domain -c 10000 -i domain 'registrant.organization:"TESLA, INC."' | jq -r .data.domain
- 通过根域名提取子域名
netlas download -d domain -c 10000 -i domain domain:"*.tesla.com" | jq -r .data.domain
- 通过组织名提取资产
netlas download -d cert -c 10000 -i certificate.names 'certificate.subject.organization:"TESLA, INC."' | jq .data.certificate.names | tr -d "\"[],"| grep -Ev "^$"| sed '/*/d' | tr -d ' ' | sort -u
# Part 8 子域名爬取
- 子域名爬取
意思就是通过第三方 API 或者开源情报信息,或者互联网留存的公开信息或者历史流量数据里面获取子域名,整个过程不涉及对域名的爆破,这样收集来的子域名也叫种子域名或者初始域名,这些域名会用到后面的进一步域名收集上,比如子域名爆破。
- Amass (慢)
amass enum --passive -d tesla.com
- Subfinder
subfinder -d tesla.com -all
github dork:
GitHub dorking 通常是通过 GitHub 的高级搜索功能来执行的,你可以在 GitHub 的搜索栏中输入特定的搜索语法来查找你感兴趣的内容或敏感信息。以下是一些常见的 GitHub dorks 及其用法:
-
查找 API 密钥:
1
filename:.env API_KEY
这将查找所有包含
.env文件并包含API_KEY的代码库。 -
查找配置文件:
1
filename:config.json
这将查找所有名为
config.json的配置文件。 -
查找密码文件:
1
filename:passwords.txt
这将查找所有名为
passwords.txt的文件。 -
查找私有仓库:
1
is:private
这将列出所有私有仓库。
-
查找安全漏洞:
1
filename:README security vulnerabilities
这将查找所有 README 文件中包含 “security vulnerabilities” 关键词的代码库。
# Part 9 子域名爆破
- 子域名爆破 (情形 1):
对根域名下面的子域名直接进行爆破 (fuzz.example.com ), 可根据需要用千万级字典
all wordlists from every dns enumeration tool… ever. Please excuse the lewd entries (github.com) (200 万级)
- PureDNS
puredns bruteforce all.txt tesla.com -r resolvers.txt
- ShuffleDNS
shuffledns -d tesla.com -w all.txt -r resolvers.txt -mode bruteforce
resolvers.txt 文件 (时刻保持最新)
resolvers/resolvers.txt at main · trickest/resolvers (github.com)
直觉或者经验告诉你有必要在某个域名花费更多的时间和精力,但一番挖掘下来又没有找到什么有用的东西,可以尝试对这个域名本身进行爆破,区别于目录爆 (admin.test.com/fuzz ), 这种情况下用小字典即可 (几千到几万量级)
有以下常见情形:
1 | wget https://raw.githubusercontent.com/trickest/resolvers/main/resolvers.txt;wget https://gist.githubusercontent.com/jhaddix/86a06c5dc309d08580a018c66354a056/raw/96f4e51d96b2203f19f6381c8c545b278eaa0837/all.txt;puredns bruteforce all.txt $domain -r resolvers.txt | sort -u | tee subs_puredns.txt; rm resolvers.txt; rm all.txt |
# Part 10 子域名劫持
- 子域名劫持 (子域名接管),是当子域指向某被删除或移除的服务时的所产生的漏洞,比如常见的有 EC2 接管,DNS 区域接管,Microsoft Azure 接管
EC2 接管与典型的子域名接管攻击 (只能修改页面) 不同,EC2 接管具有更高的危害,可以在特定情况下声明 SSL 证书、监听流量并执行帐户接管
- EC2 接管
当厂商将资产部署到 AWS 时,可能会运行具有关联 IP 的 EC2 实例,同时也创建指向这些 IP 的 DNS 记录,但在 EC2 实例被赋予新 IP 或被销毁后忘记删除 DNS 记录,则厂商很容易受到这种类型子域名接管攻击。
这个过程需要运气和自动化,假设有 100 万个域名,每天解析这 100 万个域名对应的 IP,不断从 EC2 获取 IP,并检查解析的 IP 列表里面是不是有刚刚获取到的 EC2 IP,如果有那就发现了漏洞;如果没有,那就释放 IP,继续获取,如果账号越多,那么成功率就会越高,AWS 对此的修复是封掉频繁分配 / 释放 IP 的 AWS 账户
# Part 11 S3 桶劫持
- S3 桶劫持,是指当 Amazon Web Services (AWS) 简单存储服务 (S3) 存储桶配置错误时发生的安全漏洞,允许未经授权的用户控制该存储桶
这类漏洞通常发生在两种情况下:【第一种最为常见】
* 无人认领的 S3 存储桶:如果应用程序或 DNS 记录中引用了存储桶名称,但存储桶本身未创建或已被删除,则攻击者可以创建同名存储桶,并可能拦截原始存储桶的数据
* 错误的权限:错误配置的存储桶权限可能允许未经授权的用户列出、读取、写入或删除存储桶的内容
- Nuclei
cat subs-with-http.txt | nuclei -t nuclei-templates/http/takeovers/aws-bucket-takeover.yaml
- 如何判断是否有接管的可能性?
访问域名且根目录为 / 的 URL,看到提示 “The specified bucket does not exist” 代表有戏,
但 BucketName 是亚马逊域名的话,可以跳过,不是的话,可以一试。
运行以下命令检查 DNS 记录,获取接管所需的信息 (悬空域和存储桶名称):
dig CNAME 存储桶名称
S3 桶劫持存在多种变体,因此不能仅通过查看 dns 记录来检测他
# Part 12 端⼝扫描
Nmap 应该是知名度最高的端口扫描工具,但由于其扫描速度,一般不作为检查 的首选。然后有人推荐 Masscan,这个工具确实很快,但有时会产生误报。
现在有了一个两全其美的方法。Naabu 用于初始端口扫描先检查一下 ,然后调用 Nmap 进行服务识别,以获取更详细的扫描信息
naabu -list lists.txt -p - -exclude-ports 80,443,21,22,25 -rate 20000 -c 500 -retries 2 -warm-up time 1 -silent -nmap-cli 'nmap -sV -oX scan.xml'
-exclude-ports 80,443,21,22,25:排除这些端口
-rate 20000:默认的过低
-c 500:默认 25 线程还是有点少
-retries 2:默认重连 3 次太多了,两次就行
# Part 13 技术识别
但在技术识别之前,先进行测活,把之前收集的所有的 ip 列表,域名列表,以及这些 ip / 域名开放的端⼝列表进行测活
- 测活:
cat subs.txt | httpx | tee subs_live.txt 或者 cat subs.txt | httpx -nf | tee subs_live.txt
- Nuclei
cat subs_live.txt | nuclei -t http/technologies/
- webanalyze
./webanalyze -host example.com -crawl 1 -output csv
# Part 14 技术栈识别
- Builtwith https://builtwith.com/relationships/tesla.com
用于了解网站关联性情况,识别某网站用的技术找使用相同技术的其他网站,根据相同技术的使用情况显示相关网站,这些网站可能也属于这个厂商的资产
# Part 15 Favicon 分析
- Favicon 分析 (资产归类)
现代浏览器会在网页标题左侧显示一个小图像 / 图标,该图标称为 favicon.ico,获取 favicon.ico 并计算其哈希值,根据 Favicon Hash 对域 / 子域 / IP 进行排序
- FavFreak
cat subs_live.txt | python3 favfreak.py -o output
用 fofa 可以快速获取厂商的 Favicon Hash 后在 shodan 里面搜索从 fofa 那里获取的 Favicon Hash
# Part 16 截屏
- 截屏
Gowitness 使用 Headless Chrome 获取
网站的屏幕截图
-
先用
gowitness file -f urls.txt --threads 50这条命令,对urls.txt里面的 url 进行截屏 -
运行
gowitness report serve -a vps的 ip: 端口启动报告服务器
# Part 17 爬⾍
- Burp Suite Pro (点点点就完事了)
- Hakrawler
cat subs_live.txt | hakrawler -subs > hakrawler_out.txt
- Katana
cat subs_live.txt | katana -sc -kf robotstxt,sitemapxml -jc -c 50 > katana_out.txt
- Gospider
gospider -S subs_live.txt -o gs_output -c 50 -d 2 --other-source --subs --sitemap --robots
- Gau
cat subs_live.txt | gau > gau_out.txt
- Oxdork
oxdork "site:yahoo.com" -c 100
爬虫的作用就是给你一个 测试的入口点,但不能完全依赖爬虫,
信息的收集往往不是独立的,而是多个工具和多个手法相互作用的结果
# Part 18 目录爆破
目录爆破的作用
- 隐蔽功能发现
- API 文档泄露
- 备份文件泄露
- 错误配置
- 403 绕过
- 其他
- 字典获取
https://wordlists.assetnote.io/
https://github.com/danielmiessler/SecLists/tree/master/Discovery/Web-Content
https://github.com/orwagodfather/WordList
- 不知道如何挑选字典就试一下下面的通用字典
https://github.com/danielmiessler/SecLists/blob/master/Fuzzing/403/403.md (403 绕过字典)
https://github.com/danielmiessler/SecLists/blob/master/Fuzzing/fuzz-Bo0oM.txt (4k 量级)
https://github.com/Bo0oM/fuzz.txt/blob/master/fuzz.txt (5k 量级)
https://github.com/orwagodfather/WordList/blob/main/fuzz.txt (22k 量级)
https://github.com/thehlopster/hfuzz/blob/master/hfuzz.txt (18w 量级)
https://github.com/six2dez/OneListForAll (多个量级)
- 创建一个自定义字典
按照之前的爬虫方法收集目标的 所有 URL (Burp Suite Pro, Hakrawler 等等方法),把所有结果去重后保留在一个文件,这些字典要记得保持更新,这是一个循环迭代的过程
- 获取路径字典
cat urls.txt | unfurl paths | sed 's/^.//' | sort -u | egrep -iv"\.(jpg|swf|mp3|mp4|m3u8|ts|jpeg|gif|css|tif|tiff|png|ttf|woff|woff2|ico|pdf|svg|txt|js)" | tee paths.txt
- 获取参数字典
cat urls.txt | unfurl keys | sort -u | tee params.txt
这些字典可以作为以后测试每个子域名的字典,因为是同一个厂商,所以这个子域名的路径在另一个子域名可能也有用 (参数也是同理)
feroxbuster--urlhttps://promo.indrive.com/-wpaths.txt (容易被 ban)
# Part 19 参数收集和爆破
GAP-Burp-Extension
- 参数爆破
隐藏参数的识别往往是通过状态码的变化,响应长度的变化,页面是不是反射了这个参数等等差异分析识别出来的
- Param-Miner 是 Burp Suite 比较常用的参数爆破插件
- Arjun 是比较常用的参数爆破命令行工具 (自动化可以试试,手动挖的时候不建议用)
- Burp Suite Pro Intruder 模块 是比较适合用来发现和 XSS 漏洞相关的参数
# Part 20 JavaScript 分析
JavaScript 分析:
- JSSCAN
for i in $(cat all_js.txt); do python3 /root/tools/JSSCAN/JSSCAN.py -u $i -d 2 >> JSSCAN.log; done
# Part 21 JavaScript 监控
- JSMon
# Part 22 威胁建模
- 威胁建模,针对信息收集的结果,构想可行的测试方案
在经过一系列的信息收集,我们获取了目标的子域名和 ip,获取了目标的各种 URL,还生成了针对目标的自定义字典,如果你进行 github 信息收集,可能还能搜集到目标泄露的账号密码,虽然我们收集了一系列信息,但是摆在我们面前的还有一个很头疼的问题,我们现在有数万,10 几万,甚至有时候是几十万的 URL,我们如何处理这些 URL,这些 URL 里面也许就藏着有漏洞的 URL,或者这些 URL 里面都没有漏洞,但是可能是漏洞 URL 的入口点 URL (像之前提到的 promo.indrive.com=>id.indrive.com ) 我们不可能一个一个打开这些 URL,因为这是不现实的,这也是我们接下来要讨论的话题如果说信息收集是收集到目标相关的资产信息,那么威胁建模就是从这些收集的信息再逆推回去找出可能的测试方案以及有可能有漏洞的子域名
首先比较简单的一种方法是你可以对你之前爬取到的数据过滤一下关键字
比如 grep "asp" , 这样的搜索出来的域名可以优先测试,容易出现 SQL 注入和 XSS 同理还可以 grep "php"
同理还可以 grep -E "admin|login|signup|register|registration|password|testuser|testing|firebase" 获取管理面板,登录面板等等
同理还可以 grep -E "api|apidoc|internal|secret|swagger" 获取 api 接口
还可以 grep -E "dev|stage|stg|staging|prod|qa" 获取开发,测试,暂存环境
除了刚刚方法,我们还可以通过每个域名出现的 URL 数量,按照从大到小进行排序,然后决定测试哪个域名。某种意义上说,出现的 URL, 出洞的概率越大,隐藏的功能点越多,当然不排除脏数据的可能。另外需要注意的是,这个判断方法不适用主要域名,虽然主要域名可能功能更多,但受到的关注也更多,安全系数也更高
# Part 23 信息收集框架
列出两个常用的:
- reconFTW
- reNgine
主要使用它们的子域名收集和截图相关的功能,不指望它可以扫出什么漏洞,大部分挖洞的过程应该在 Burp suite 手动进行。而且大部分的时候,我会重新进行目录爆破,因为需要生成自定义字典以适配目标厂商,同时设置适当的过滤规则防止太多误报的输出
- Title: Information Gathering
- Author: Fc04dB
- Created at : 2024-07-08 16:11:39
- Updated at : 2024-08-28 14:50:42
- Link: https://redefine.ohevan.com/2024/07/08/Information-Gathering/
- License: This work is licensed under CC BY-NC-SA 4.0.